High Availability Clustering Failover Support
High Availability (HA) clustering provides a fault-tolerant HMP streaming solution. This licensed service is based on a cluster of three identically-provisioned servers (one primary and two secondary), plus one NFS server to serve as a media repository (not provided by Haivision).
The primary server provides all services, while the secondary servers maintain a state of active readiness (online, but not providing services). This redundancy ensures that if the primary server fails, one of the secondary servers seamlessly assumes all services with minimal interruption. See the following section for scenarios which the cluster can recover from.
Note
The HA feature does not guarantee fully uninterrupted service. In the event of a primary server failure, there is a momentary service interruption followed by automatic recovery. This failover takes a few seconds during which some interruption is unavoidable.
All HMP HA clusters must be implemented by Haivision Field Services.
List of Recoverable Scenarios
The following table contains of a list of scenarios where the HMP-HA cluster will or will not recover:
Hardware components | Recoverable? |
|---|---|
Hardware component outage of the primary node 1 |
|
Primary node of the cluster is down |
|
Hardware component outage of a secondary node while the first node is also down 2 |
|
Primary and secondary nodes are down 2 |
|
Power failure | Recoverable? |
Partial power failure; each server is connected to a different power source and 2 servers are still powered |
|
Complete power failure; all nodes are not powered |
|
Network | Recoverable? |
Primary server is unable to communicate with the network or is disconnected |
|
Complete network outage; all servers are unable to communicate with the network |
|
1 Individual application and Operating System failures on the primary node do not trigger a failover to a secondary node. Examples include web server, “disk full” errors, recording errors, or failure to connect to directory services.
2 HMP-HA is not operational with only one working node.
Implementation Details
There are four components essential to achieving high availability with HMP:
Redundant servers — HMP HA is based on a cluster of three identically provisioned servers that are managed automatically. As stated previously, the primary node provides all services, while the secondary nodes maintain a state of active readiness.
Note
The additional servers in an HMP HA cluster do not increase HMP performance in any way.
A mixture of HMP server appliances and HMP virtual machines for the HA cluster is not supported.
Database replication — All three nodes maintain a local copy of the HMP database which stores all of the data necessary for operations, including user and asset permissions, asset metadata and index, usage history, licensing and system configuration. To keep the secondary nodes ready to assume the role of primary node at all times, their database copies are continuously synchronized to ensure they are an exact replica of the primary node (using HMP’s native support for MongoDB Replica Sets (MRS)).
Cluster virtualization and health monitoring — Each HMP HA cluster node runs a
keepalivedservice that continually monitors and reports on the status of critical services and communications between the HMP nodes. If the primary node fails, thekeepalivedservice triggers a failover event. This service also monitors the network interfaces for all nodes, and presents a persistent virtual IP address that transparently provides access to HMP services to downstream Haivision Media Gateways, STBs, mobile devices, and end users. The devices or end users do not need to be aware of which cluster member is currently serving as the primary node.Shared storage — All HMP HA cluster nodes must have NFS access to a shared media asset repository (e.g., NAS) that stores recordings and other binary data, such as custom branding logos, thumbnails, and poster images that are not critical to live streaming operations (and thus not stored in the HMP database). This NFS server must be provided by the customer and must sustain the recommended file I/O throughput for a given HMP configuration. While all HMP nodes must have access to the same NFS mount point, only the primary node actively writes to the NFS server.
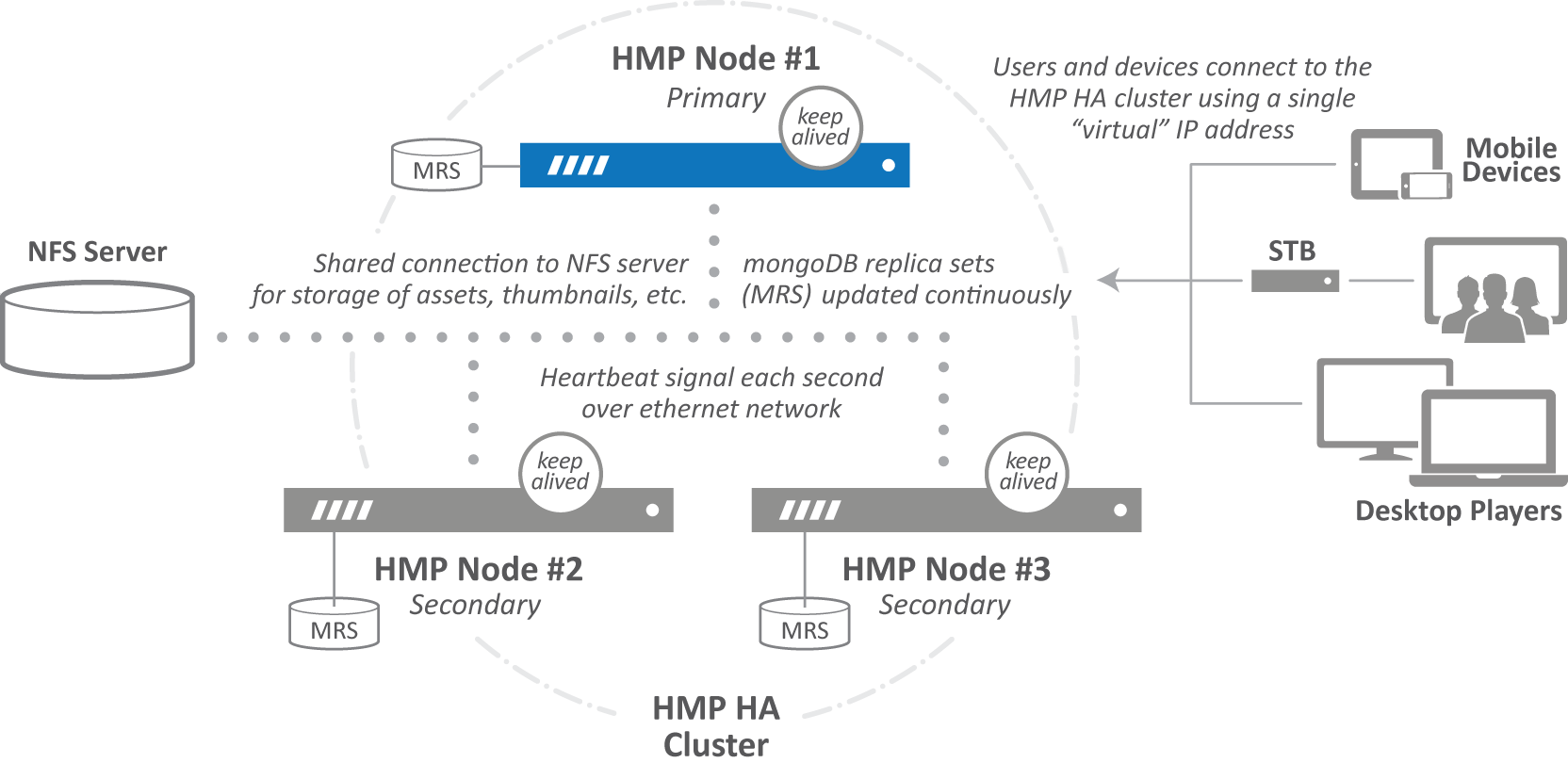
HMP HA Cluster Diagram
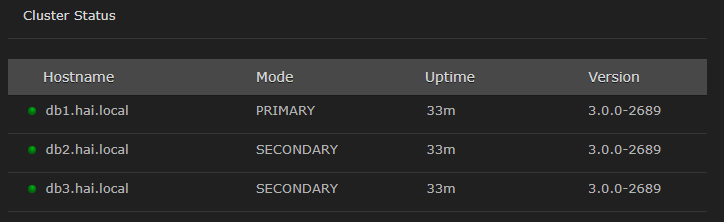
The HA cluster status is visible in the HMP UI for system administrators to monitor each node. See Viewing High Availability Cluster Status for more details.
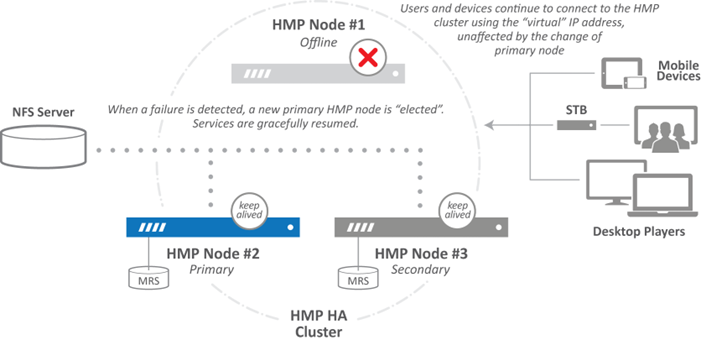
How Failover Works
A failover is triggered when one of the following conditions occurs on the primary node:
The cluster heartbeat signal (monitored by
keepalived) is interrupted by a hardware problem that renders the server inoperative/unreachable (e.g. power loss, ethernet cable unplugged) or a freeze/crash of the server's operating systemA critical failure of the database instance on the primary node
When a failover occurs, the primary node’s services are taken offline and a secondary HMP node is immediately reconfigured to the primary role. This failover takes place within seconds, and typically goes unnoticed by downstream gateways and clients. The HA cluster, now reduced to two servers, continues to function normally while the failed server is fixed and brought back online.
If either of the two remaining nodes fails, the entire cluster goes offline (i.e., it stops responding to HMG, end user, or device requests) to ensure there is no risk to database or user data integrity. Normal operations resume when at least two out of the three nodes in the HA cluster are properly functioning. As nodes are restored, the cluster automatically determines which node is primary.
For more details and information on HA licensing, contact your Haivision representative or the Haivision Support Portal.
Related Topics